URL encoding — also called percent-encoding — is how browsers and APIs represent spaces, symbols, and non-ASCII text inside web addresses and form payloads. If you have ever seen %20 where you expected a space, or a broken link after copying from a document, you have met encoding in the wild. This guide explains what URL encoding is, how to encode and decode correctly, and when to use each option. When you are ready, open our free URL Encode & Decode tool to fix strings instantly in your browser.
Fix %20 errors now: Open the URL Encode & Decode tool — live UTF-8 mode, 50+ character sets, recursive decode, file upload, and copy-ready results. No signup.
Overview
Meet URL Decode and Encode, a simple online tool that does exactly what it says: decodes from URL encoding as well as encodes into it quickly and easily. URL encode your data without hassles or decode it into a human-readable format.
URL encoding, also known as “percent-encoding”, is a mechanism for encoding information in a Uniform Resource Identifier (URI). Although it is known as URL encoding it is, in fact, used more generally within the main Uniform Resource Identifier (URI) set, which includes both Uniform Resource Locator (URL) and Uniform Resource Name (URN). As such it is also used in the preparation of data of the application/x-www-form-urlencoded media type, as is often employed in the submission of HTML form data in HTTP requests.
What is URL encoding?
URIs may only contain a limited set of characters. Everything else must be converted to bytes and written as %XX where XX is hexadecimal. For UTF-8 text, each byte of the character's encoding is percent-encoded separately — so a space (byte 20) becomes %20, and an emoji may become several % sequences.
Reserved characters (RFC 3986 §2.2)
These characters have special meaning in some URI components: ! * ' ( ) ; : @ & = + $ , / ? # [ ]
Unreserved characters (RFC 3986 §2.3)
Letters A–Z a–z, digits 0–9, and - _ . ~ never need encoding. Producers should not encode unreserved characters for maximum interoperability.
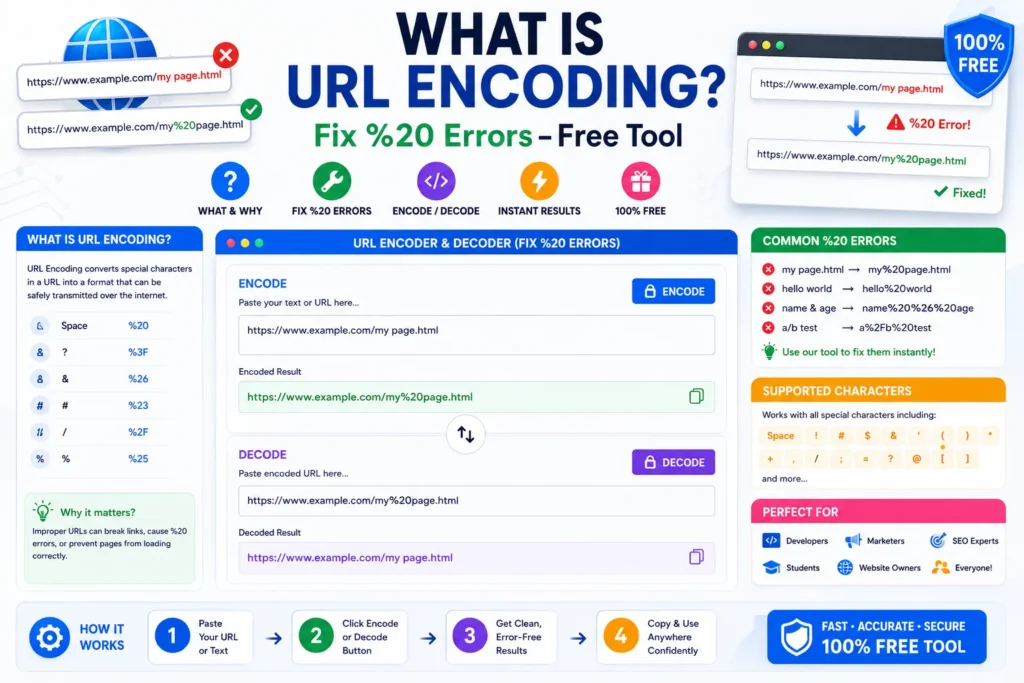
How to encode and decode URLs (step by step)
- Paste your text or URL into the encode or decode panel on the URL Encode & Decode tool.
- Choose options — character set, newline separator, line-by-line mode, MIME chunks, or live UTF-8 mode.
- Click ENCODE or DECODE (or turn on live mode for instant UTF-8 results).
- Copy or download the output and paste into your app, CMS, or API client.
Advanced options
Character set: Our website uses the UTF-8 character set, so your input data is transmitted in that format. Change this option if you want to convert the data to another character set before encoding. Note that in case of text data, the encoding scheme does not contain the character set, so you may have to specify the appropriate set during the decoding process. As for files, the binary option is the default, which will omit any conversion; this option is required for everything except plain text documents.
Newline separator: Unix and Windows systems use different line break characters, so prior to encoding either variant will be replaced within your data by the selected option. For the files section, this is partially irrelevant since files already contain the corresponding separators, but you can define which one to use for the “encode each line separately” and “split lines into chunks” functions.
Encode each line separately: Even newline characters are converted to their percent-encoded forms. Use this option if you want to encode multiple independent data entries separated with line breaks. (*)
Split lines into chunks: The encoded data will become a continuous text without any whitespaces, so check this option if you want to break it up into multiple lines. The applied character limit is defined in the MIME (RFC 2045) specification, which states that the encoded lines must be no more than 76 characters long. (*)
Live mode: When you turn on this option the entered data is encoded immediately with your browser's built-in JavaScript functions, without sending any information to our servers. Currently this mode supports only the UTF-8 character set.
(*) These options cannot be enabled simultaneously since the resulting output would not be valid for the majority of applications.
Formulas and encoding rules
For a byte value b that is not unreserved:
encoded = "%" + uppercase_hex(b) // e.g. space (0x20) → %20
For UTF-8 character C:
bytes = UTF8(C)
output = concat( percentEncode(byte) for each byte in bytes )Example: Path segment my page.html → my%20page.html
Double encoding warning: Encoding an already-encoded string produces %2520 for a space. Use recursive decode (up to 16 passes) to recover.
Common characters after percent-encoding
| Character | Encoded (UTF-8 / ASCII) |
|---|---|
| newline | %0A or %0D or %0D%0A |
| space | %20 |
| " | %22 |
| % | %25 |
| & | %26 |
| + | %2B |
| / | %2F |
| ? | %3F |
| # | %23 |
| = | %3D |
Use cases
| Scenario | Why encoding matters |
|---|---|
| Query string parameters | Values with &, =, or spaces break parsing unless encoded. |
| Redirect URLs in analytics | UTM tags and landing-page URLs must be encoded when nested inside another URL. |
| HTML form POST bodies | application/x-www-form-urlencoded uses percent-encoding; spaces may appear as +. |
| API clients & webhooks | JSON string fields copied into URLs need encoding before HTTP requests. |
| Internationalized paths | Non-ASCII slugs are UTF-8 bytes percent-encoded per RFC 3986. |
| Debugging broken links | Decode to find double-encoding, wrong charset, or stray + characters. |
| Email and SMS links | Line wraps and smart punctuation often introduce spaces that require %20. |
Common mistakes and solutions
| Mistake | Problem | Solution |
|---|---|---|
| Space left unencoded in URL | Browser or server rejects link; SEO tools flag errors | Encode spaces as %20 using the encoder |
| Encoding an entire URL including scheme | https:// becomes unusable |
Encode only the path or individual query values |
| Double (or triple) encoding | %2520 instead of %20 |
Enable recursive decode or fix at source |
| Wrong character set on decode | Mojibake — garbled accents | Match ISO-8859-1 vs UTF-8 to the producing system |
Using + in path segment |
Some servers treat + literally, not as space |
Use %20 in paths; + is mainly for form bodies |
| Encoding reserved chars that are delimiters | Breaking query structure | Encode values, not ? & = that separate parameters |
| Mixing encode-each-line with MIME chunks | Invalid output for most parsers | Enable only one of these options at a time |
Safe and secure
All communications with our servers come through secure SSL encrypted connections (https). When you use live mode or text panels, encoding runs in your browser — pasted content is not sent for processing. Uploaded files are processed locally in JavaScript; ShoutingNow does not retain file contents on servers. Read our privacy policy for full details.
Completely free
Our tool is free to use. From now on, you don't need to download any software for such simple tasks.
Details of URL encoding
Percent-encoding reserved characters
When a reserved character has special meaning in a particular context and must appear as data, it is percent-encoded: the character is converted to its byte value and written as % plus two hex digits. The reserved character / in a path segment, for example, must appear as %2F when it is data rather than a delimiter.
Percent-encoding the percent character
Because % indicates an encoded octet, a literal percent sign in data must be encoded as %25.
Binary and character data
Binary data in URIs is divided into 8-bit bytes and percent-encoded. Character data outside ASCII should use a defined charset (UTF-8 on the modern web). Legacy systems that omit charset metadata cause ambiguous URIs — always document or agree on UTF-8 when possible.
Fix your URLs now
Use the ShoutingNow URL Encode & Decode tool to encode query values, decode analytics URLs, or process files with BINARY mode. Bookmark this URL encoding tutorial for RFC tables, formulas, and troubleshooting — then share the tool with your team for unlimited free use.